Crosstable is a package centered on a single function, crosstable, which easily computes descriptive statistics on datasets. It can use the tidyverse syntax and is interfaced with the package officer to create automatized reports.
Installation
# Install last version available on CRAN
install.packages("crosstable")
# Install development version on Github
remotes::install_github("DanChaltiel/crosstable@v0.9.0.9008")Note that, for reproducibility purpose, an even better solution would be to use renv.
Overview
Here are 2 examples to try and show you the main features of crosstable. See the documentation website for more.
Example #1
Dear crosstable, using the
mtcars2dataset, please describe columnsdispandvsdepending on the levels of columnam, with totals in both rows and columns, and with proportions formatted with group size, percent on row and percent on column, with no decimals.
library(crosstable)
ct1 = crosstable(mtcars2, c(disp, vs), by=am, total="both",
percent_pattern="{n} ({p_row}/{p_col})", percent_digits=0) %>%
as_flextable()
ct1
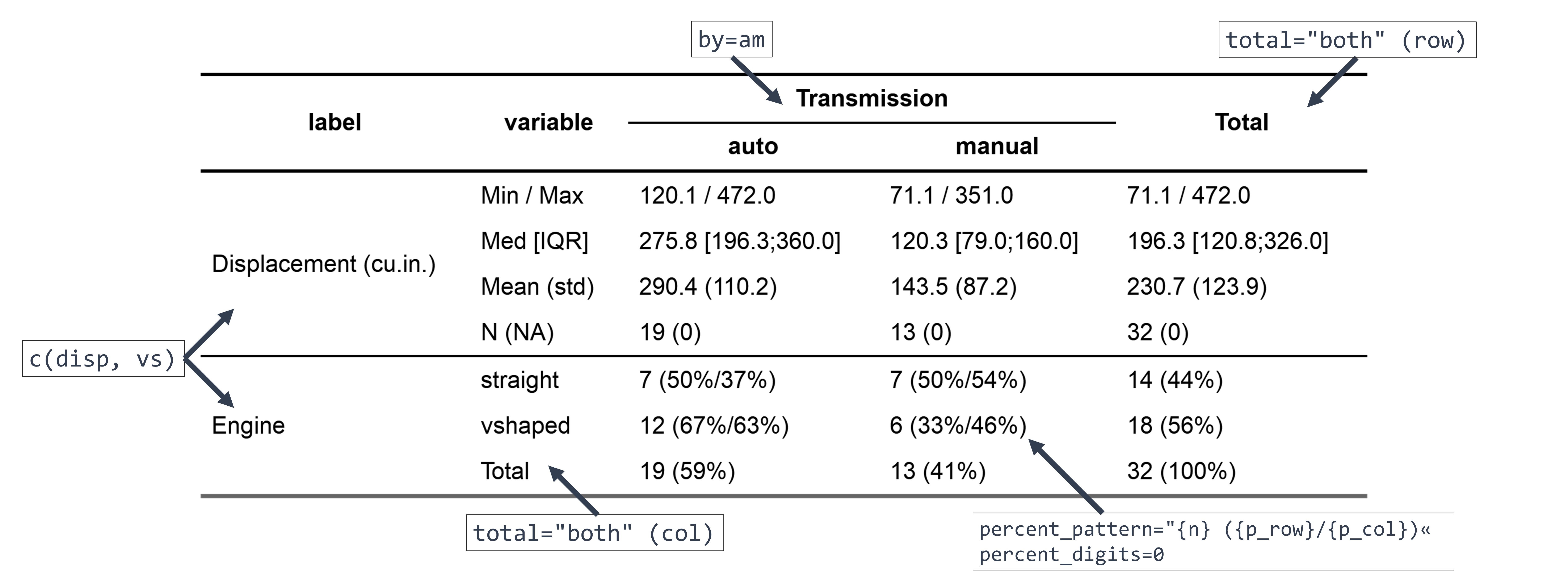
With only a few arguments, we did select which column to describe (c(disp, vs)), define a grouping variable (by=am), set the percentage calculation in row/column (percent_pattern=), and ask for totals (total=).
Since mtcars2 is a dataset with labels, they are displayed instead of the variable name (see here for how to add some).
As crosstable() is returning a data.frame, we use as_flextable() to output a beautiful HTML table. This one can even be exported to MS Word with a few more lines of code (see here to learn how).
Example #2
Here is a more advanced example.
Dear crosstable, using the
mtcars2dataset again, please describe all columns whose name starts with “cy” and those whose name ends with “at”, depending on the levels of both columnsamandvs, without considering labels, applyingmean()andquantile()as summary function, withprobs25% and 75% defined for this latter function, and with 3 decimals for numeric variables:
ct2 = crosstable(mtcars2, c(starts_with("cy"), ends_with("at")), by=c(am, vs),
label=FALSE, num_digits=3, funs=c(mean, quantile),
funs_arg=list(probs=c(.25,.75))) %>%
as_flextable(compact=TRUE, header_show_n=1:2)
ct2
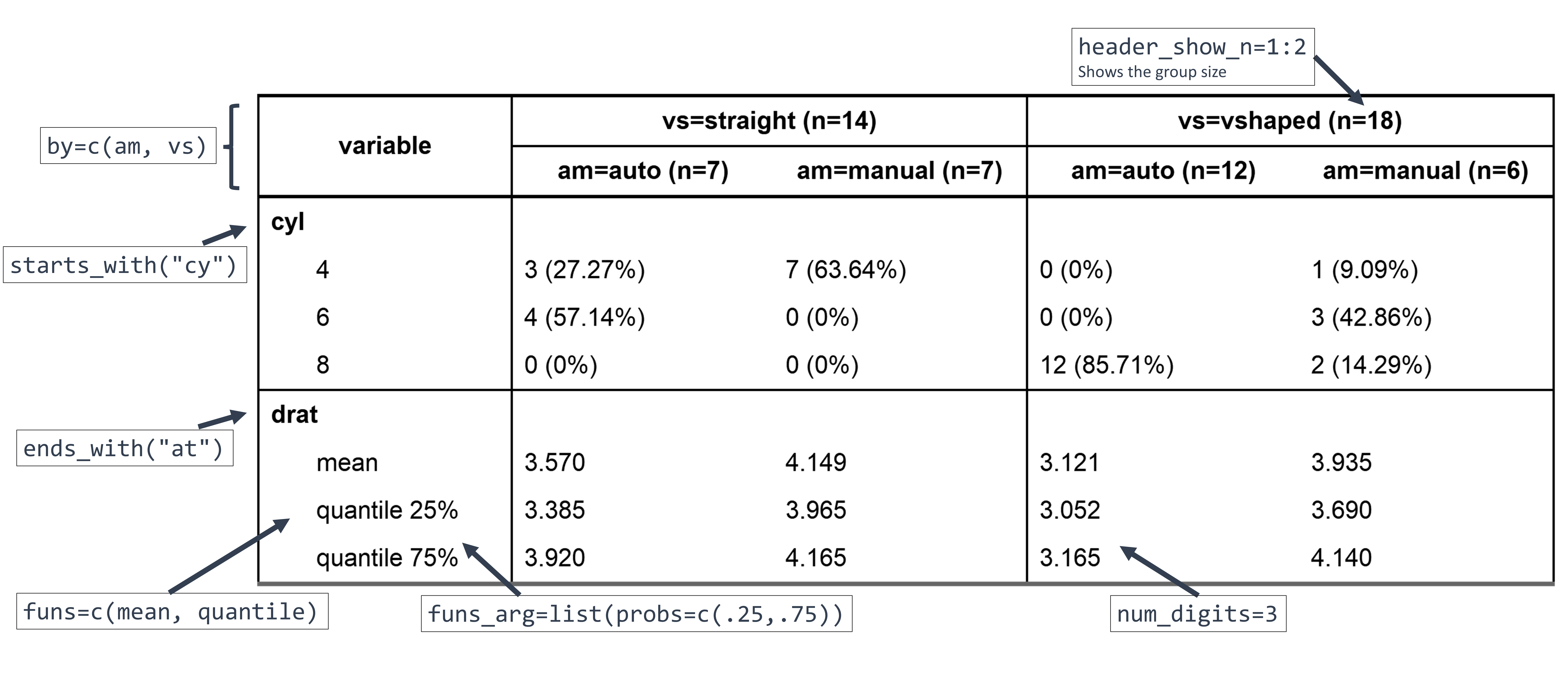
Here, the variables were selected using tidyselect helpers and the summary functions mean and quantile were specified, along with argument probs for the latter. Using label=FALSE allowed to see which variables were selected but it is best to keep the labels in the final table.
In as_flextable(), the compact=TRUE option yields a longer output, which may be more suited in some contexts (for instance for publication), and header_show_n=1:2 adds the group sizes for both rows of the header.
Documentation
You can find the whole documentation on the dedicated website:
-
vignette("crosstable")for a first step-by-step guide on how to usecrosstable(link) -
vignette("crosstable-report")for more on creating MS Word reports using either officer orRmarkdown(link) -
vignette("pertent_pattern")for more on how to usepercent_pattern(link) -
vignette("crosstable-selection")for more on variable selection (link), although you should better read https://tidyselect.r-lib.org/articles/syntax.html.
There are lots of other features you can learn about there, for instance (non-exhaustive list):
- description of correlation, dates, and survival data (link)
- variable selection with functions, e.g.
is.numeric(link) - formula interface, allowing to describe more mutated columns, e.g.
sqrt(mpg)orSurv(time, event)(link) - automatic computation of statistical tests (link) and of effect sizes (link)
- global options to avoid repeating arguments (link)
Getting help and giving feedback
If you have a question about how to use crosstable, please ask on StackOverflow with the tag crosstable. You can @DanChaltiel in a comment if you are struggling to get answers. Don’t forget to add a minimal reproducible example to your question, ideally using the reprex package.
If you miss any feature that you think would belong in crosstable, please fill a Feature Request issue.
If you encounter an unexpected error while using crosstable, please fill a Bug Report issue. In case of any installation problem, try the solutions proposed in this article first.
Acknowledgement
In its earliest development phase, crosstable was based on the awesome package biostat2 written by David Hajage. Thanks David!